現如(rú)今,日本等國家(jiā)少子化與老齡化的日趨嚴重,勞動力也變得(dé / de / děi)越來越緊缺,工作方式的改革又需要(yào / yāo)業界提高生(shēng)産效率。爲同時解決這兩大難題,利用(yòng)機器人實現業務自(zì)動化的RPA(機器人流程自(zì)動化)技術引起了社會(huì)廣泛關注。以金融業爲主的各個行(háng / xíng)業已開始引入RPA技術,并取得(dé / de / děi)了顯著成果。比如(rú)說,實現了自(zì)動創建文檔與錄入數據錄等功能(néng)。
目前,市面上已經出現了能(néng)夠将語音自(zì)動轉換成文字的人工智能(néng)軟件。但由于(yú)精準的文字轉換難度超出想象,對(duì)于(yú)會(huì)議、演講等記錄工作,我們不得(dé / de / děi)不繼續采用(yòng)人工方式。
我們該如(rú)何解決這一問題呢?――東芝給出的方案是全新開發(fā/fà)的人工智能(néng)語音識别系統。
爲了解人工智能(néng)語音識别系統的需求背景和開發(fā/fà)過(guò)程需要(yào / yāo)突破的技術難題,我們咨詢了東芝株式會(huì)社研究開發(fā/fà)中心的兩位負責人——蘆川先生(shēng)與藤村先生(shēng)。
一、快速準确地将語音轉換成文字,并通過(guò)清晰字幕實時顯示!
東芝一直緻力于(yú)拓展智能(néng)媒體領域的業務(智能(néng)媒體是對(duì)人類語音和圖像進行(háng / xíng)知識處理,并加以靈活應用(yòng)的技術)。長年(nián)積累的技術開發(fā/fà)經驗極大地推動了人工智能(néng)語音識别系統的開發(fā/fà)。
此次開發(fā/fà)項目的研讨工作始于(yú)2015年(nián)。那(nà)一年(nián)恰逢“信息無障礙”環境建設的風口,日本政府号召民衆,努力打造一個便于(yú)殘障人士無障礙地獲取各類信息的社會(huì)環境。對(duì)此,東芝早早就(jiù)開始了通用(yòng)設計産品和服務的開發(fā/fà)工作,建立了成熟的通用(yòng)設計(UD)顧問制度,并邀請身體有殘障的員工參與産品開發(fā/fà)。
蘆川先生(shēng)表示:“聽覺障礙人士的普遍心聲是希望實時參與會(huì)議和講演,而(ér)不是通過(guò)事(shì)後(hòu)查看文字記錄的方式來了解會(huì)議與講演内容。我們的計劃是引入一個能(néng)夠自(zì)動顯示實時文字信息的字幕,方便聽覺障礙人士了解相關内容,從而(ér)幫助殘障人士實現‘信息獲取’與‘效率提升’兩大目标。人工智能(néng)語音識别系統的開發(fā/fà)工作正是朝着(zhe/zhuó/zhāo/zháo)這兩大目标進行(háng / xíng)的。”(蘆川先生(shēng))

株式會(huì)社東芝 研究開發(fā/fà)中心
人工智能(néng)媒體實驗室 研究主任 蘆川平
二、提高算法的準确度,語音識别率高達85%!
接觸過(guò)文字轉換的朋友都深有體會(huì):将對(duì)話、講義及講演等語音忠實、完整地轉換成文字,反而(ér)會(huì)變成一篇晦澀難懂的文章。轉換後(hòu)的文字信息會(huì)出現很多冗餘的内容,比如(rú):“嗯”、“那(nà)個”等無意義詞語,以及對(duì)理解内容毫無幫助的随聲附和語句等。
此次的人工智能(néng)語音識别系統能(néng)夠精準地識别出說話人的語音,并且可(kě)以分辨出無意義的詞語和停頓部分。這一功能(néng)對(duì)于(yú)提高工作效率極爲重要(yào / yāo)。人工智能(néng)的核心是算法,據說爲了提高算法的準确度,開發(fā/fà)團隊設立了各種各樣的課題并進行(háng / xíng)了深入研究。
“在開始階段,我們屢屢碰壁,發(fā/fà)現提高識别精度是非常困難的一件事(shì)。我們的目的不在于(yú)開發(fā/fà)和研究本身。說到底,我們的目的是爲用(yòng)戶帶來方便。通過(guò)采用(yòng)日漸流行(háng / xíng)的LSTM1模型以及CTC學習2手段,能(néng)夠根據語音特征,識别出人類特有的無意義詞語、停頓等部分”(藤村)
1 LSTM(長短期記憶):RNN(遞歸神經網絡)的一種高級形式,其(qí)隐藏層中含有遞歸結構。能(néng)夠對(duì)長期依賴關系進行(háng / xíng)學習,而(ér)這種學習能(néng)力是傳統RNN無法實現的。
2 CTC(聯結主義時間分類):針對(duì)輸入輸出的序列長度差異問題,通過(guò)引入空字符和設計損失函數的方法,來導入RNN的手段。

株式會(huì)社東芝 研究開發(fā/fà)中心
人工智能(néng)媒體實驗室 主任研究員 藤村浩司
傳統的語音識别系統是采用(yòng)分析波形的方法,将不同波形的語音确定爲相應假名,例如(rú):“ア”或“イ”等,然後(hòu)進行(háng / xíng)分析。但是,無意義詞語和停頓的波形千變萬化,存在無數種形式,采用(yòng)逐一分析的方式是無法窮盡的。
“無意義詞語是填充話語之間的空白部分,而(ér)停頓則是話語之間的休息片斷。通過(guò)LSTM模型能(néng)夠把話語中的這些部轉換爲統計模型,然後(hòu)再通過(guò)CTC對(duì)模型進行(háng / xíng)識别訓練。這樣一來,就(jiù)能(néng)夠檢測出擁有無數種形式的無意義詞語、停頓部分了。
目前尚無一家(jiā)公司能(néng)夠開發(fā/fà)出完全準确的語音識别系統。更廣闊的開發(fā/fà)空間和更高的技術等待着(zhe/zhuó/zhāo/zháo)我們去(qù)探索。我們的語音識别系統目前能(néng)夠支持日語、英語、漢語三種語言,但這遠遠不夠,我們的終極目标是讓不同語種的人士可(kě)以圍坐于(yú)圓桌旁輕松暢聊,讓科幻小說和漫畫中的未來場景在現實中一一實現。當然,那(nà)需要(yào / yāo)超高的準确度,可(kě)以說我們開發(fā/fà)工作就(jiù)是讓夢想照進現實。”(藤村)
目前,我們的人工智能(néng)語音識别系統識别精度很高,在同行(háng / xíng)業具有很大優勢。當我們利用(yòng)外部演講機會(huì)進行(háng / xíng)實證(實際驗證)實驗時,語音識别率平均達到85%。而(ér)且無需對(duì)識别結果進行(háng / xíng)編輯,也不需要(yào / yāo)相關人員事(shì)先進行(háng / xíng)學習,就(jiù)能(néng)理解發(fā/fà)言内容。未來我們将繼續提高語音識别準确度,研讨如(rú)何将其(qí)應用(yòng)到人工智能(néng)交流系統「RECAIUS™」領域。
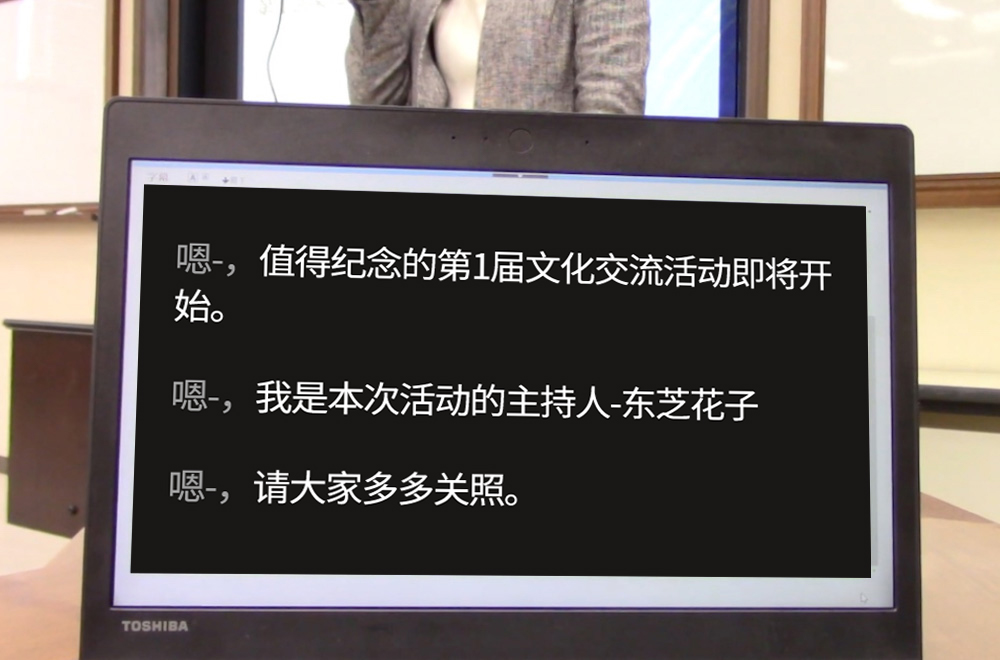
我們也在進行(háng / xíng)相關應用(yòng)程序的開發(fā/fà)。比如(rú)說,面向聽覺障礙人士開發(fā/fà)的實時字幕顯示功能(néng)。由人工智能(néng)檢測出的無意義詞語和停頓并不是被全部删除掉,而(ér)是以淺色字體形式顯示在字幕中,讓聽覺障礙人士意識到這些詞語的存在。這是充分聽取殘障人士們的意見後(hòu),從他們的角度出發(fā/fà),制定的精細化字幕顯示方案。

聲音自(zì)動字幕系統(左)和字幕顯示圖像(右)
“對(duì)我們而(ér)言,像‘嗯’、‘那(nà)個’這種無意義詞語隻是會(huì)影響我們的閱讀。但是,聽覺障礙人士希望獲取到完整的信息。他們通常是跟随說話人的嘴唇運動來閱讀字幕,如(rú)果将無意義詞語和停頓部分删除,就(jiù)會(huì)給他們帶來‘好像說了些什麽,但字幕上沒有顯示’的感受,從而(ér)産生(shēng)焦躁情緒。
因此,我們将無意義詞語和停頓部分也保留在字幕中,但爲方便閱讀,将這些部分顯示爲淺色字體。當我們需要(yào / yāo)保存記錄時,可(kě)以删掉這些部分,制作成一份簡潔的文檔。”(蘆川先生(shēng))
三、用(yòng)于(yú)制造業的人工智能(néng)已見雛形,在生(shēng)産現場發(fā/fà)揮真正的價值!
2019年(nián)3月,我們有幸與DWANGO株式會(huì)社合作,通過(guò)NICONICO網站對(duì)“第81屆信息處理學會(huì)全國大會(huì)”的實況進行(háng / xíng)現場直播,此次直播采用(yòng)了帶有實時字幕的視頻形式。
爲了早日投入商業使用(yòng),東芝開發(fā/fà)團隊正在努力提高人工智能(néng)語音系統的識别準确度和各項功能(néng)。此外,東芝面向的不僅是辦公業務,還包括生(shēng)産現場。
“現實情況是,幾乎所(suǒ)有辦公環境都未将人工智能(néng)語音識别系統作爲一項服務加以靈活應用(yòng)。在我看來最理想的狀态是,人工智能(néng)語音識别系統能(néng)夠得(dé / de / děi)到用(yòng)戶信賴而(ér)被廣泛應用(yòng),最終成爲一項日常業務。比如(rú)說,我現在所(suǒ)說的這些話能(néng)夠被完整地識别,并且記錄成業務級别的文檔形式,同時還能(néng)根據發(fā/fà)言人的不同,分辨并區别記錄。我們要(yào / yāo)實現的目标正是這種方便可(kě)靠的人工智能(néng)語音識别系統”(蘆川先生(shēng))
“目前,語音識别業務并不普及,生(shēng)産現場也是如(rú)此。但是,在維修檢查時,以及工廠的某些特定場景,确實需要(yào / yāo)用(yòng)免提電話記錄聲音。在這種情況下(xià),人工智能(néng)語音識别系統一定會(huì)大顯身手的。将語音識别系統無縫融入生(shēng)産現場,便于(yú)工人們将産生(shēng)于(yú)現場的智慧與經驗記錄和傳遞。當然,這需要(yào / yāo)進行(háng / xíng)長期的語音識别系統開發(fā/fà),并在生(shēng)産及基礎設施現場積累足夠的知識經驗後(hòu)才能(néng)夠實現。我認爲這正是東芝開發(fā/fà)語音識别系統的根本目的之一。”(藤村)
目前,日本存在着(zhe/zhuó/zhāo/zháo)勞動力緊缺的問題。預計進入“2020年(nián)代”後(hòu),勞動力緊缺問題将更加嚴重。我們的當務之急是節省人力,提高生(shēng)産效率,确保聽覺障礙人士順利獲取信息。在未來,辦公環境和生(shēng)産現場對(duì)于(yú)人工智能(néng)語音識别系統的需求一定會(huì)不斷增長,人工智能(néng)語音識别系統必将大展身手。








 滬公網安備 31010102002443号
滬公網安備 31010102002443号